


Quant Chronicles: DeltaLake—A Powerful Data Management System
Welcome to the third installment of Quant Chronicles. 🚀

Managing data effectively is a cornerstone of the quant lifecycle. As quant developers, our mission is clear: design platforms that minimize the time researchers spend collecting, sorting, and interpreting vast amounts of data. 📊
With the explosive growth of both traditional and non-traditional data, choosing the right data management solution is more critical than ever.
In this article, I’ll explore DeltaLake, a powerful and increasingly popular data management system. Why focus on DeltaLake? My curiosity stems from firsthand experience. Early in my career, I built a Fixed-Income systematic quant platform that relied on Sybase for data extraction and persisted it into Parquet files. While I appreciated the performance benefits of a robust file-based system, I quickly encountered limitations—particularly around scalability and advanced data management capabilities.
In large organizations, quant developers often don’t control the data ingestion process. Instead, we act as data consumers, sourcing information from established data warehouses and combining it with other sources. 🏗️ Our primary challenge is to create a unified, normalized environment where we can transform, validate, and persist data efficiently. This is where DeltaLake shines.
But what exactly is DeltaLake, and why has it gained traction in the quant community? To answer these questions, I turned to Delta Lake: The Definitive Guide, an excellent resource available for free through Databricks or with an O’Reilly account.
The Evolution of Data Management
The rise of data lakehouses has revolutionized data management, bridging the gap between traditional data warehouses and data lakes. 🌉 A data lakehouse combines the scalability and flexibility of data lakes with the reliability and performance of data warehouses. Here’s how DeltaLake fits into this evolution:
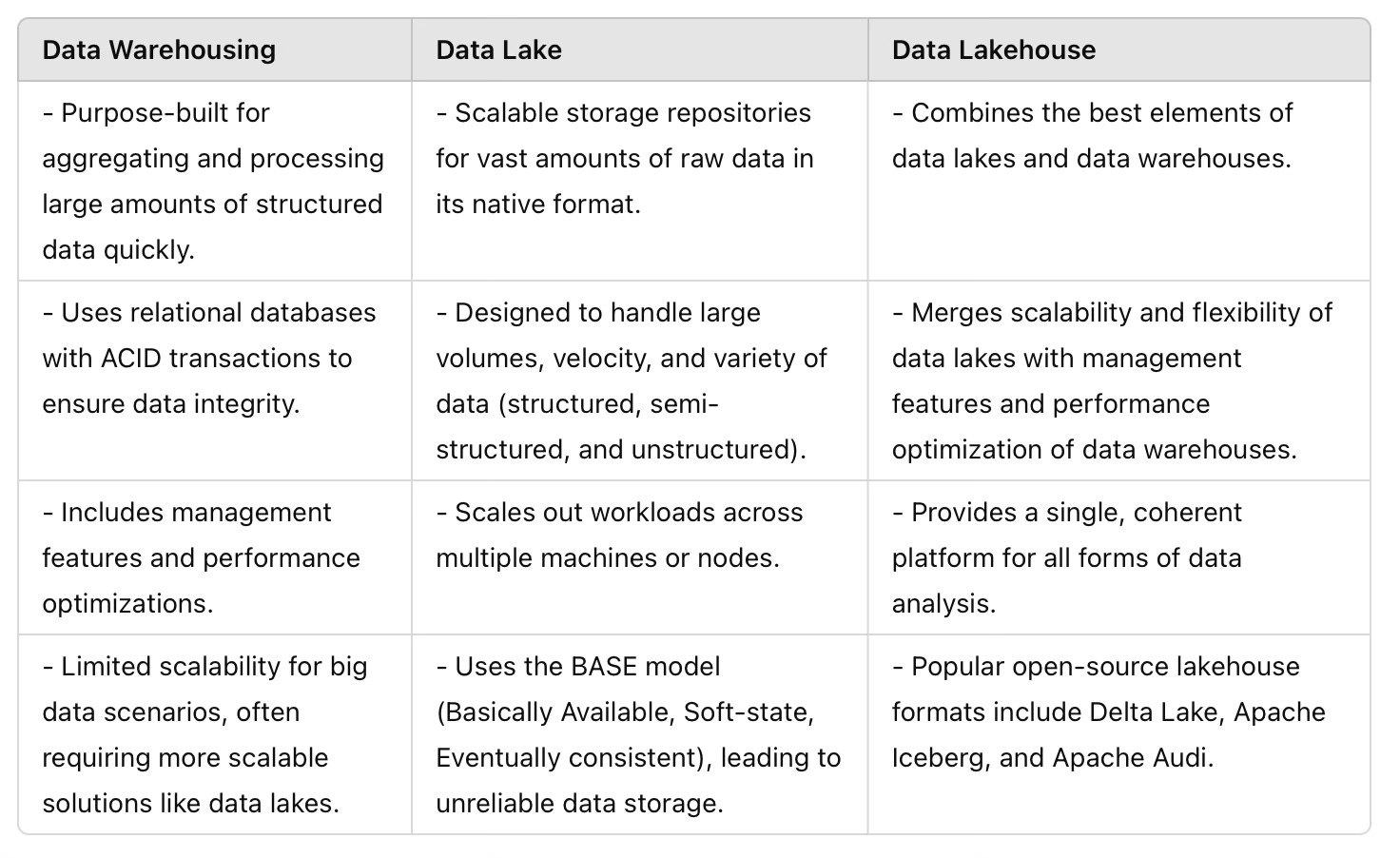
Delta Lake: A Closer Look
DeltaLake is an open-source storage layer that supports ACID transactions, scalable metadata handling, and the integration of streaming and batch processing.
"Delta lake was one of the first lakehouse formats to provide data manipulation language (DML) operations. This initially extended Apache Spark to support various operations such as insert, update, delete and merge (or CRUD operations). Today, users can effectively modify the data using multiple frameworks, services, and languages."
Delta Lake: The Definitive GuideKey Features of Delta Lake
Data Manipulation Language (DML)
DeltaLake offers robust data manipulation capabilities, including support for complex operations like merge. It provides multiple modes for writing data, such as:
Append: Adds new records to the dataset without altering existing data.
Overwrite: Replaces the entire dataset with new data.
Overwrite with Predicates: Updates specific parts of the dataset while retaining unaffected data.
Ignore: Prevents duplicate writes by skipping data that already exists.
Schema Enforcement
DeltaLake includes a schema_mode parameter to manage data schemas effectively.
None: Fails if the schema doesn’t match.
Merge: Combines new data schema with the existing one.
Overwrite: Replaces the existing schema entirely.
Additional guardrails, such as data type validation and null value handling, ensure consistency and prevent errors during data writes.
Delta Lake Time Travel
A standout feature of DeltaLake is its transaction log, or "delta log," which links metadata and data, enabling users to view or restore older versions of a dataset. Known as time travel, this feature is invaluable for:
Auditing and compliance: Reconstructing previous data states for verification. 🔍
Versioned pipelines: Querying data as it existed at specific points in time. 🕒
What Do You Think? 🤔
DeltaLake represents a significant step forward in the evolution of data management systems. Its combination of scalability, flexibility, and reliability makes it a natural fit for the demands of the quant lifecycle.
🧩 If you’re ready to tackle the challenges of modern data management, DeltaLake is worth exploring.
Are you using DeltaLake in your quant workflows? Let me know your thoughts and experiences in the comments below! 🗨️
Related articles:
