
Quant Chronicles: The Case for Point-In-Time Data
Welcome to the second installment of Quant Chronicles. 🚀

Have you ever grappled with Point-In-Time (PIT) data? If you’ve worked in the quant world, it’s almost guaranteed. Think about IBES data, WorldScope Fundamentals, payroll numbers — the list goes on.
When designing a quant platform, considering Point-In-Time data is essential. In recent discussions, I encountered two highly polarized perspectives:
On one side, some argue that versioning alone is sufficient.
On the other, some insist that a platform cannot function effectively without PIT logic.
Combining intuition with experience, I realized that both viewpoints are valid depending on the use case. Naturally, I needed evidence to present a compelling case to my colleagues. 🧠📚
Clarifying the Basics 🛠️
Through various end-user requests, literature reviews, and personal exploration, I’ve encountered multiple definitions of Point-In-Time data, which can sometimes lead to confusion. Let’s start with the basics:
Data versioning refers to the process of maintaining and managing different versions of datasets over time.
Point-In-Time data is timestamped and recorded exactly as it was originally reported, preserving any subsequent revisions alongside the original data.
After reading these definitions multiple times, I keep coming back to the idea that they’re not opposing solutions but complementary ones. Isn’t Point-In-Time data simply a more detailed approach to data versioning?
An Illustrative Example 💡
I came across a fantastic report by S&P Global, "Point-In-Time vs. Lagged Fundamentals," which examines the distinctions between PIT and Non-PIT data and their implications for backtesting and investment analysis. While I encourage you to read the full report for a deeper understanding, here’s an example from it to illustrate PIT data:
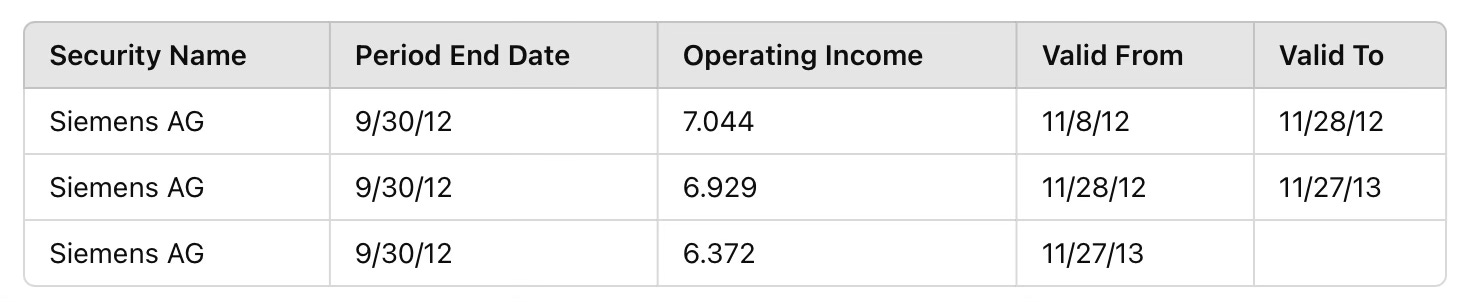
This table illustrates how data evolves over time. 📈 For backtesting, it’s critical to use the data valid at a specific point. In contrast, while a versioning system might log changes, programmatically accessing them for backtesting can be complex and expensive.
Why is Extracting Data Valid at a Specific Point in Time Crucial?
Quant researchers are particularly concerned with look-ahead bias, as it leads to misleading results and ineffective signals. PIT data ensures signals are based solely on information available at the time, maintaining the integrity of strategies and avoiding the contamination of future data.
Is PIT Necessary for Every Dataset? 🤔
In my bias opinion, the answer is no. To evaluate this, I consider two factors: the data type and the data stage.
Before diving into these factors, let me clarify: PIT data in this article is represented by “valid from” and “valid to” columns, implying that these dates refer to the time during which the values are applicable.
Data Type 📋
In the literature, PIT data is frequently associated with fundamentals. A key characteristic of fundamental data is its projection and estimation aspect. For instance, in the table above:
The first data point (7.044) represents an estimate.
The second (6.929) represents the actual value.
The third (6.372) reflects a restated value.
This demonstrates a natural data lifecycle where values for the same period might change. It’s important to distinguish between restatements and corrections:
Restatements are part of the normal lifecycle of a data point.
Corrections address errors in the originally published data.
Players such as Refinitiv and FactSet offer comprehensive suites of PIT products for fundamental data that are widely used by the industry.
On the other hand, consider using prices as an example. Fixed Income prices, derived daily through vendor-proprietary evaluation methods, do not necessarily require PIT data. Prices aren’t (ever) exactly matching between vendors, and when questioning a vendor about a price, they will likely say, “We will adjust the price on a forward basis.” In this case, corrections may happen, but there are no estimates or projection lifecycles for the data points. I would argue that if a price is corrected, the backtest value should use the corrected one. High-frequency trading shops may disagree with me, but I am yet to come across such a strategy for Fixed Income to build a proper opinion.
Of course, there are other examples where PIT data is important and they are not fundamentals. Examples include:
PIT data for On-The-Run treasuries.
PIT data for credit ratings, which is crucial when creating a composite credit rating and knowing which rating across agencies is applicable at a given moment.
Data Stage 🏠
Understanding the stage of the data helps determine whether PIT logic is essential. In everyday processes, the cycle typically goes as follows: data is acquired from the vendor, passes through an ETL process to stage it in a database (in future posts, we will discuss these solutions in detail), and the model extracts the data to perform signal construction, optimization, and other steps for investment strategies.
I view PIT as an early step in the process, where the data acquired by the vendor is preserved with minimal transformation to ensure very little information is lost. This enables researchers to discover the data and extract it to meet their needs.
PIT may be unnecessary in post-processing related to model execution. Models extract data, apply their logic, and transform data such that the PIT aspect is absorbed. In systematic workflows, each model run represents a unique point in time, rendering dates redundant for subsequent processing steps.
Key Takeaway 🎯
We must avoid imposing a one-size-fits-all approach. Instead, understanding the specific requirements and characteristics of each dataset is crucial. By tailoring our methods to the data at hand, we can avoid over-engineering and focus on building efficient, adaptable quant platforms that empower researchers and preserve the integrity of quantitative strategies.
What Do You Think? 🤔
Did I miss anything obvious, or do you have a different perspective? I’d love to hear your thoughts on Point-In-Time data and how it fits into your quant workflows. Let’s continue the conversation!